Detecting small objects
Why field of view matters
AI Okinawa
Kuba Kolodziejczyk
Profile
名前: Kuba Kolodziejczyk
出身: ポーランド
大学: ロンドン大学, 大阪大学
過去
Nanyang Technological University
OIST
レキサス
現在
AI Okinawa - 代表
LiLz株式会社 - CTO
琉球大学 - 非常勤講師
出身: ポーランド
大学: ロンドン大学, 大阪大学
過去
Nanyang Technological University
OIST
レキサス
現在
AI Okinawa - 代表
LiLz株式会社 - CTO
琉球大学 - 非常勤講師

Single shot detector
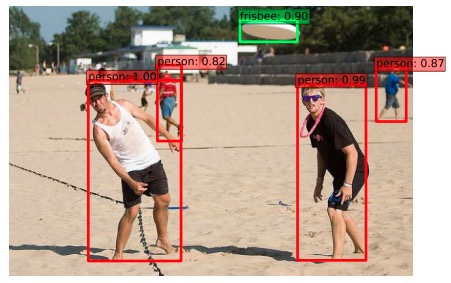
SSD: Single Shot MultiBox Detector - sample detections
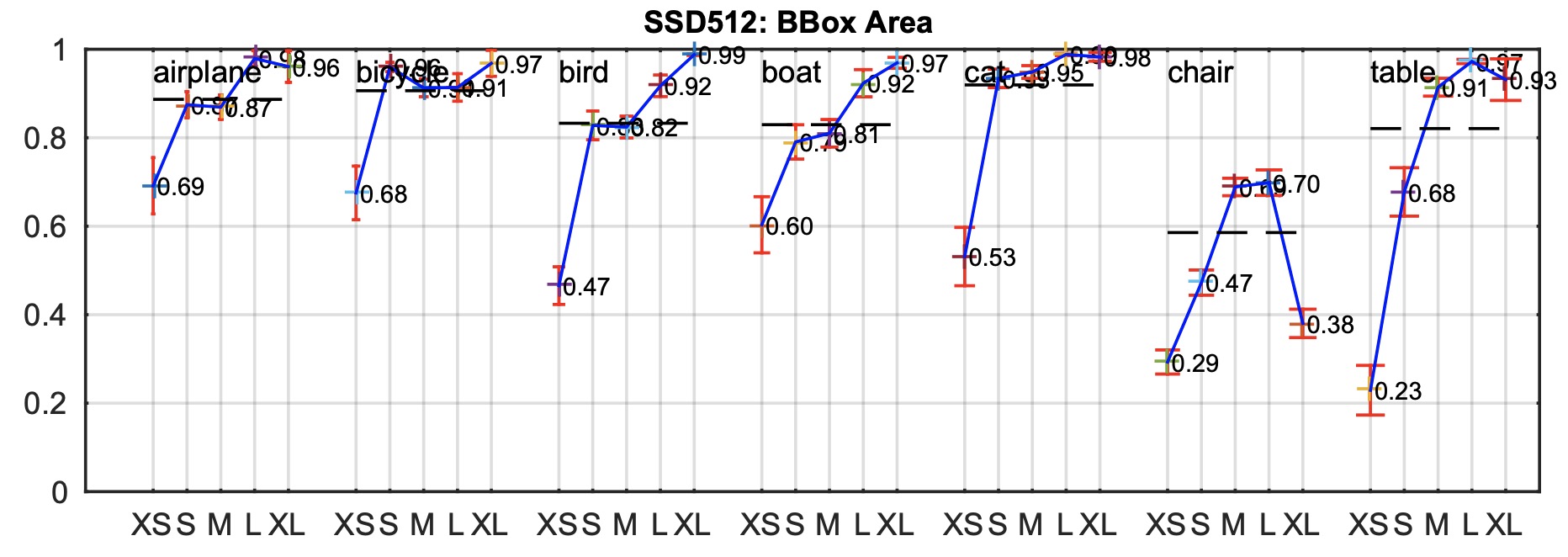
SSD: Single Shot MultiBox Detector - classification accuracy across objects sizes on VOC dataset
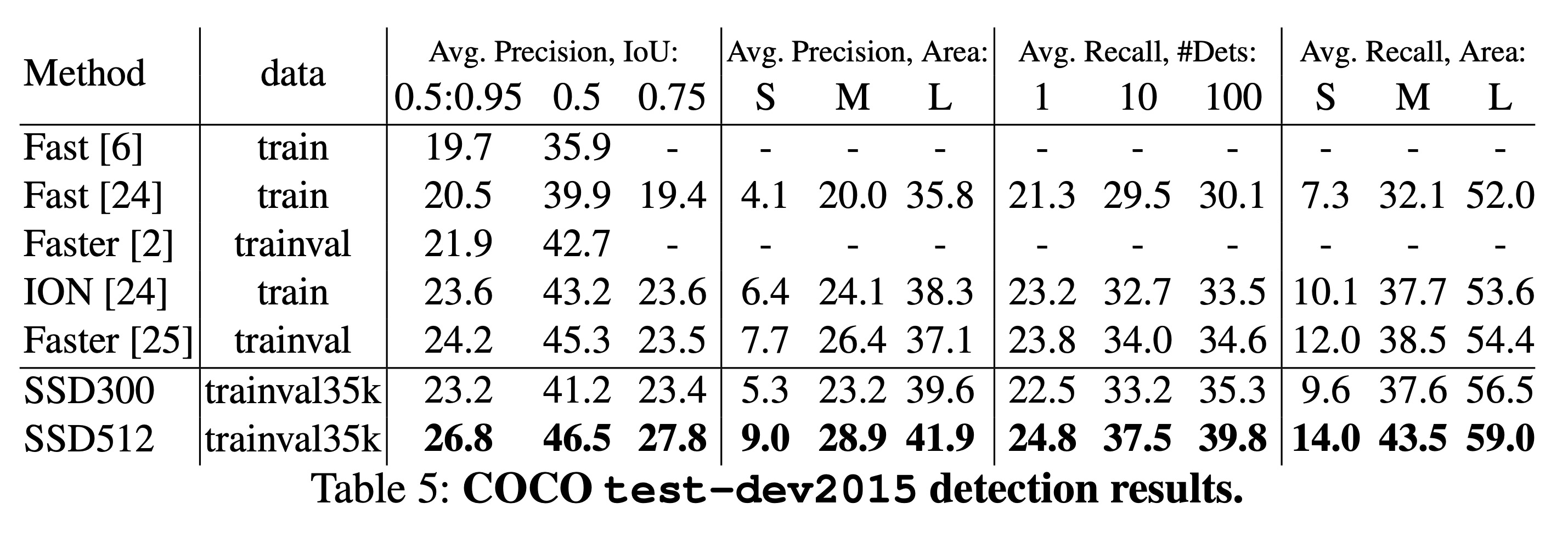
SSD: Single Shot MultiBox Detector - recall accuracy across objects sizes on COCO dataset
Convolutions
$$ I_j^{l+1} = f( \sum_{j} ( I_{j + z}^l * k_z ) + b ) $$
| \( I_0^1 \) | \( I_1^1 \) | \( I_2^1 \) | \( I_3^1 \) | \( I_4^1 \) |
| \( k_0 \) | \( k_1 \) | \( k_2 \) |
| \( I_0^2 \) | \( I_1^2 \) | \( I_2^2 \) |
| \( I_0^2 = f( (I_0^1 * k_0) + (I_1^1 * k_1) + (I_2^1 * k_2) + b ) \) |
| \( I_1^2 = f( (I_1^1 * k_0) + (I_2^1 * k_1) + (I_3^1 * k_0) + b ) \) |
| \( I_2^2 = f( (I_2^1 * k_0) + (I_3^1 * k_1) + (I_4^1 * k_0) + b ) \) |
| \( I_0^1 \sim I_2^1 \) | \( I_1^1 \sim I_3^1 \) | \( I_2^1 \sim I_4^1 \) |
Convolutions - more layers
| \( I_0^1 \) | \( I_1^1 \) | \( I_2^1 \) | \( I_3^1 \) | \( I_4^1 \) |
| \( I_0^1 \sim I_2^1 \) | \( I_1^1 \sim I_3^1 \) | \( I_2^1 \sim I_4^1 \) |
| \( I_0^1 \sim I_4^1 \) | \( I_1^1 \sim I_5^1 \) | \( I_2^1 \sim I_6^1 \) |
Pooling
$$ I_j^{l+1} = max(I_{2j}^l, I_{2j+1}^l) $$
| \( I_0^1 \) | \( I_1^1 \) | \( I_2^1 \) | \( I_3^1 \) | \( I_4^1 \) | \( I_5^1 \) |
| \( I_0^2 \) | \( I_1^2 \) | \( I_2^2 \) |
| \( I_0^2 = max(I_0^1, I_1^1) \) |
| \( I_1^2 = max(I_2^1, I_3^1) \) |
| \( I_2^2 = max(I_4^1, I_5^1) \) |
| \( I_0^1 \sim I_1^1 \) | \( I_2^1 \sim I_3^1 \) | \( I_4^1 \sim I_5^1 \) |
Pooling - more layers
| \( I_0^1 \) | \( I_1^1 \) | \( I_2^1 \) | \( I_3^1 \) | \( I_4^1 \) | \( I_5^1 \) |
| \( I_0^1 \sim I_1^1 \) | \( I_2^1 \sim I_3^1 \) | \( I_4^1 \sim I_5^1 \) |
| \( I_0^1 \sim I_3^1 \) | \( I_4^1 \sim I_7^1 \) | \( I_8^1 \sim I_{11}^1 \) |
Two convolutional blocks
| convolution 3x3 |
| convolution 3x3 |
| convolution 3x3 |
| pooling 2x2 |
| \( I_0^1 \) | \( I_1^1 \) | \( I_2^1 \) | \( I_3^1 \) | \( I_4^1 \) | \( I_5^1 \) |
| \( I_0^1 \sim I_2^1 \) | \( I_1^1 \sim I_3^1 \) | \( I_2^1 \sim I_4^1 \) |
| \( I_0^1 \sim I_4^1 \) | \( I_1^1 \sim I_5^1 \) | \( I_2^1 \sim I_6^1 \) |
| \( I_0^1 \sim I_6^1 \) | \( I_1^1 \sim I_7^1 \) | \( I_2^1 \sim I_8^1 \) |
| \( I_0^1 \sim I_7^1 \) | \( I_2^1 \sim I_9^1 \) | \( I_4^1 \sim I_{11}^1 \) |
| \( I_0^1 \sim I_{11}^1 \) | \( I_2^1 \sim I_{13}^1 \) | \( I_4^1 \sim I_{15}^1 \) |
| \( I_0^1 \sim I_{15}^1 \) | \( I_2^1 \sim I_{17}^1 \) | \( I_4^1 \sim I_{19}^1 \) |
| \( I_0^1 \sim I_{19}^1 \) | \( I_2^1 \sim I_{21}^1 \) | \( I_4^1 \sim I_{23}^1 \) |
| \( I_0^1 \sim I_{21}^1 \) | \( I_4^1 \sim I_{25}^1 \) | \( I_8^1 \sim I_{29}^1 \) |
Single shot detector - objects sizes vs fields of view
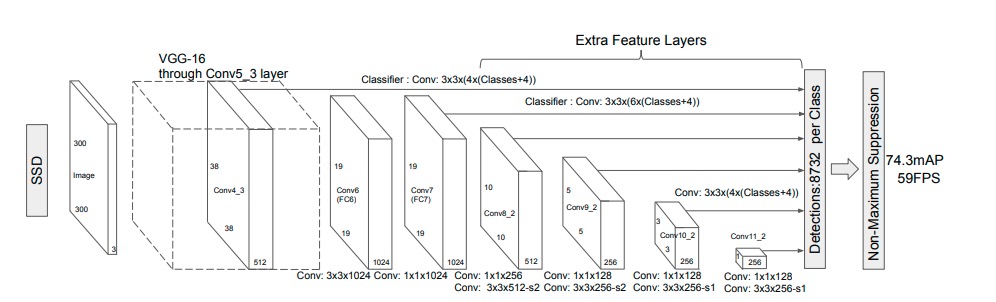
SSD: Single Shot MultiBox Detector - architecture
| \( I_0^1 \sim I_{212}^1 \) | \( I_{33}^1 \sim I_{224}^1 \) | \( I_{65}^1 \sim I_{276}^1 \) |
- max(width, height) > 100 px:
8.9% - max(width, height) < 50 px:
70.6%
Pascal VOC objects sizes analysis
213x213 window
213x213 window reduced to 1x1
ProblemField of view too large to detect small objects
Solution
Add prediction head at block with field of view slightly above desired object sizes
| \( I_0^1 \sim I_{75}^1 \) | \( I_{8}^1 \sim I_{83}^1 \) | \( I_{17}^1 \sim I_{91}^1 \) |
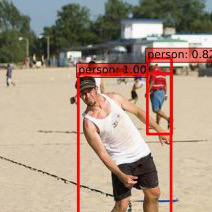
(Top secret VOC-like dataset)
- Precision:
~70% - Recall:
~20%
Before
- Precision:
~80% - Recall:
~80%
After
Summary
- Convolutional layers have associated fields of views
- Convolutional layers are compressing data
The larger your field of view, the less fine-grained information you retain Small objects can be detected if you use layers with appropriate fields of views for the task- Aim for field of view 1.2x~1.5x of objects sizes to provide layers some context
